Introduction/Summary
Emails, Web pages, social media, chat, survey responses, etc. are some of the channels through which customers communicate with a company or organization. The data or text messages coming through these channels are unstructured. Due to its unstructured nature it is difficult to extract insight like, whether the customer is happy or not, whether it is spam or not and what is the category of text. If we receive 100 mails from customers in a day and are asked to identify the percentage of positive and negative response then it will be very difficult and time consuming.
To solve this problem, we can now think of using Text classification model of AI Builder. In this blog, we will see how to use Text classification model to identify positive and negative responses coming through emails.
If you have not read our previous blog on AI Builder please go through it. You will learn how to enable AI Builder feature and how to create “Form processing model” to extract forms or documents.
Now let’s start with Text classification model.
Prepare Data
The success of Text classification model depends on data that we are using to train the model. Before we build the Text classification model, we must check the prerequisites, data format of data that we are going to use to train the model. Check the following article for the same. https://docs.microsoft.com/en-us/ai-builder/before-you-build-text-classification-model
Basically, here we need to,
- Create a new custom entity in CDS to store Text and their associated tags
- Create a csv file with Text and Tags. Separate tags by a delimiter like comma, semicolon, pipe etc.
- Import csv data to CDS.
Below is the sample data that we have created to try this (Text classification model, AI Builder) feature,
Name column for primary key field, Tags column to store tags in semicolon separated and Text column to store text.

If you do not have sufficient data then model may not work correctly. So make sure that you have at least 50 text of each tags. For example, 50 different text of Positive tag and 50 different text of Negative tags.
Create, Train and publish a Text classification model
- Sign in to https://web.powerapps.com
- Click on AI Builder(Preview) > Build
- Select ‘Text classification’ and click on ‘Create’
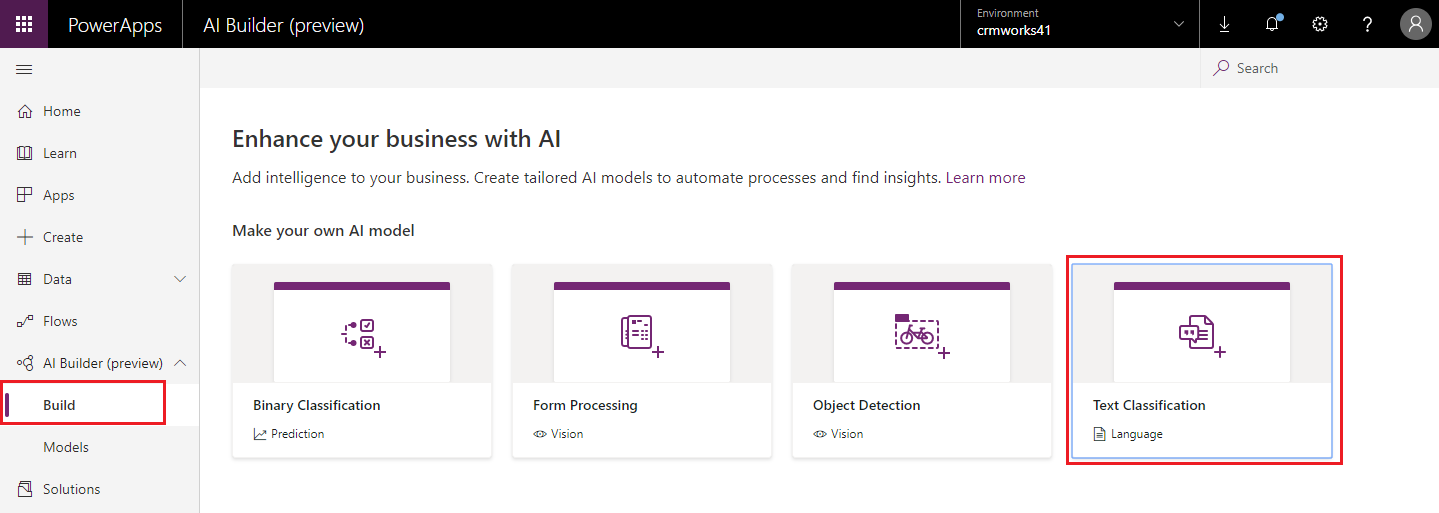
- Below screen will pop-up. Give name to the model. Here, we can also see the examples which gives an idea about how the data should be.
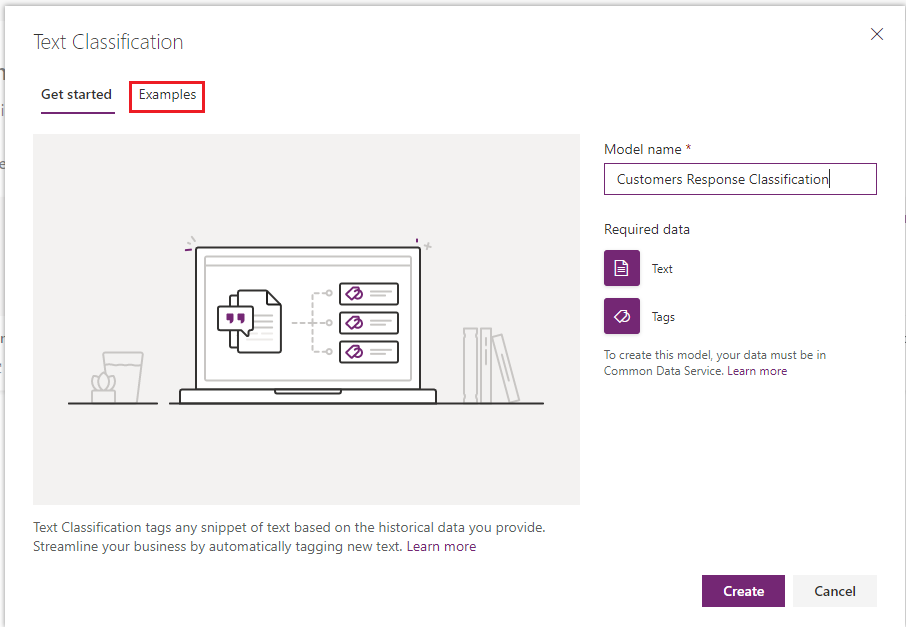
- In next screen, select Text and select Tags. Map Text to the field of custom entity where text is stored and map Tags to the field of custom entity where tags are stored. Here we have created and selected a custom entity called ‘Text Classification Data’.
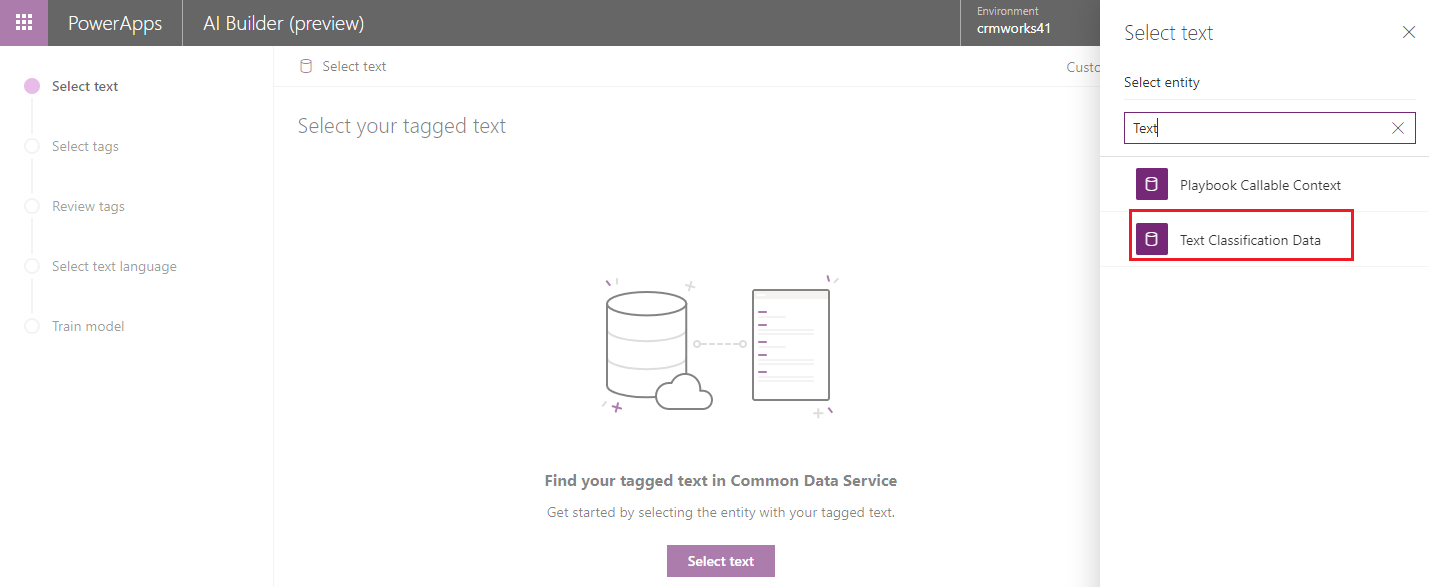
- After text selection, we will be able to see the preview of text that are available in CDS and that is going to be used for training.
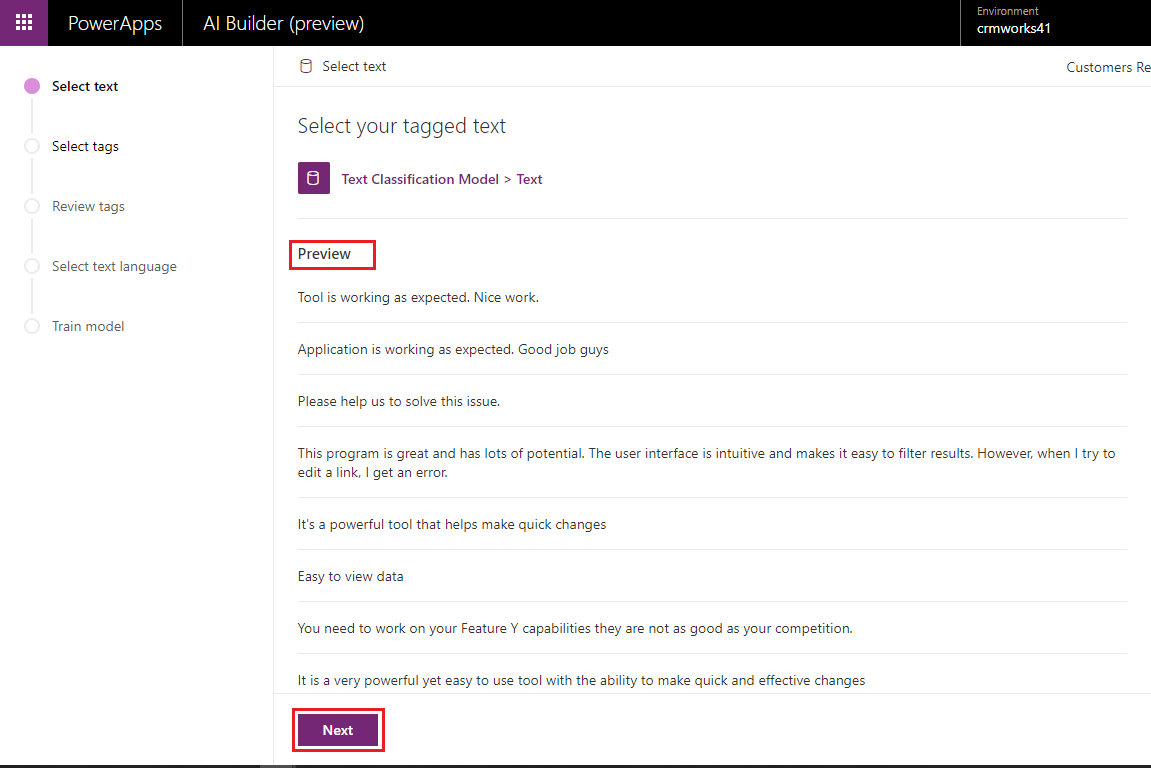
- Click on Next button and select field for Tags. Here ‘Text Classification Data’ is custom entity and ‘Tags’ is multiline text field.
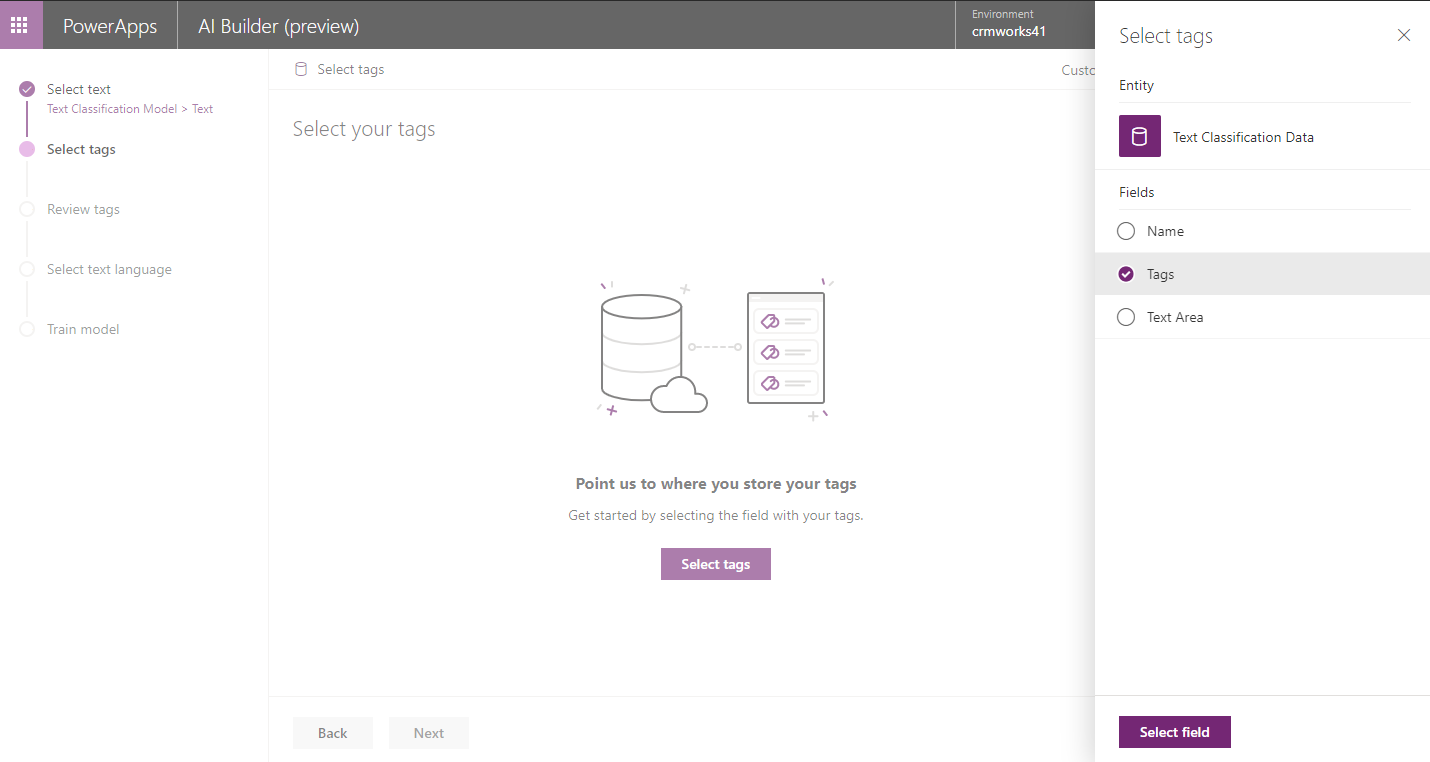
- In next screen, select the tag separator. If you have imported the tags separated by semicolon or comma or tab then select semicolon or comma or tab respectively.
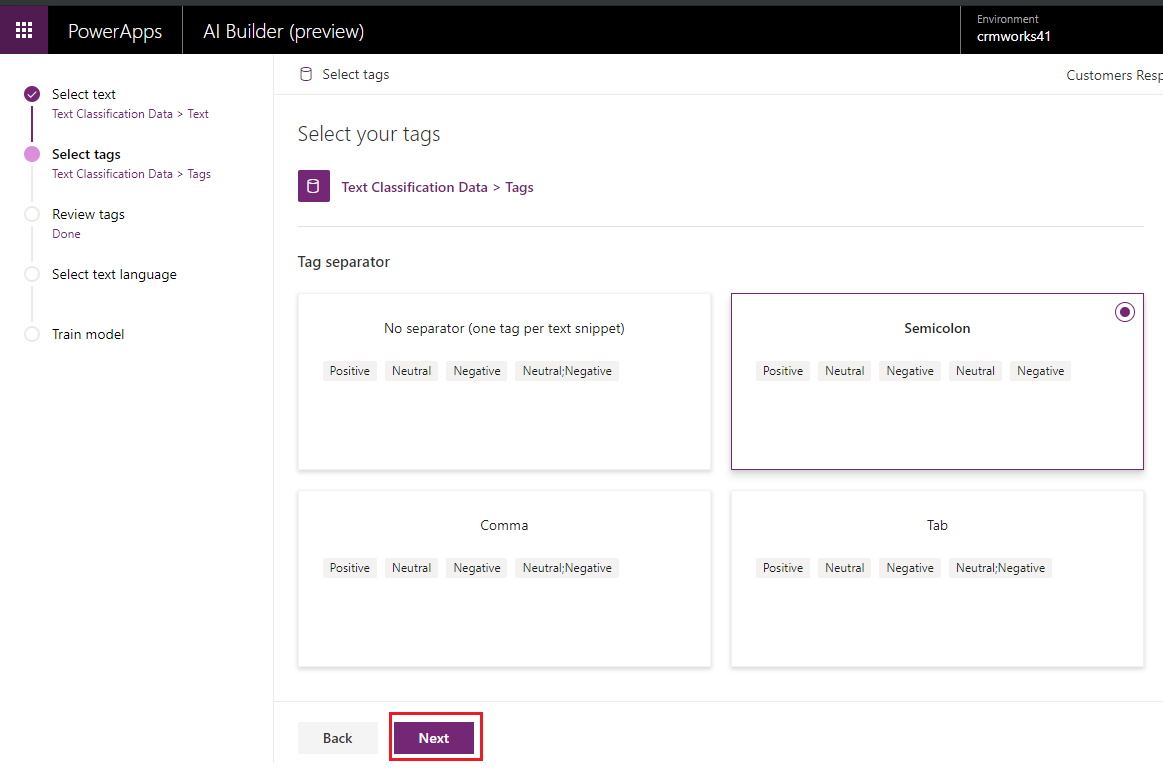
- Click on Next button and review the tags.
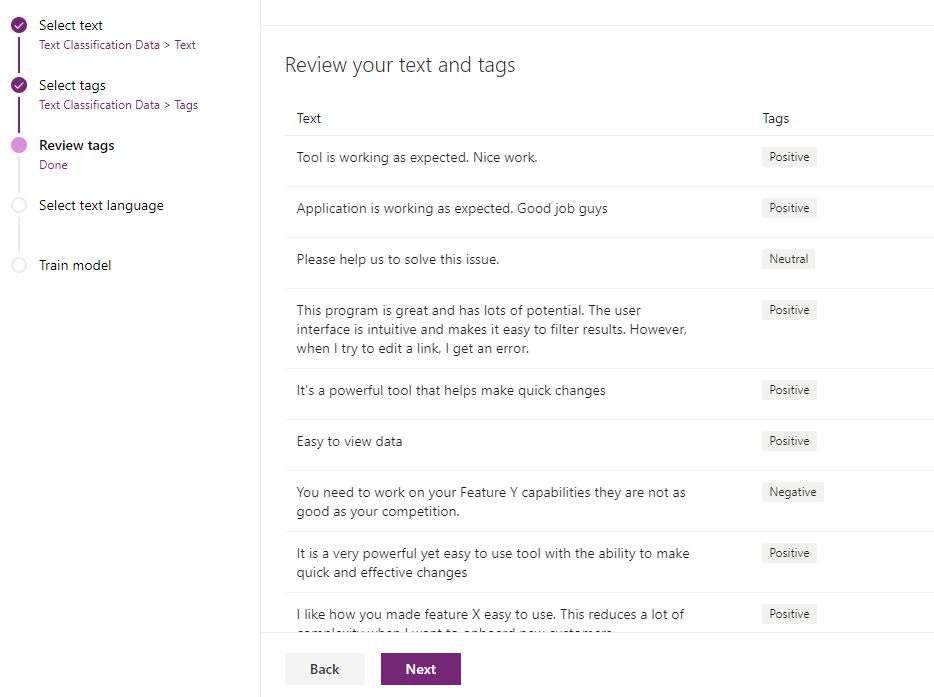
- Select language from the list of available languages. AI model uses this selected language to analyze text.
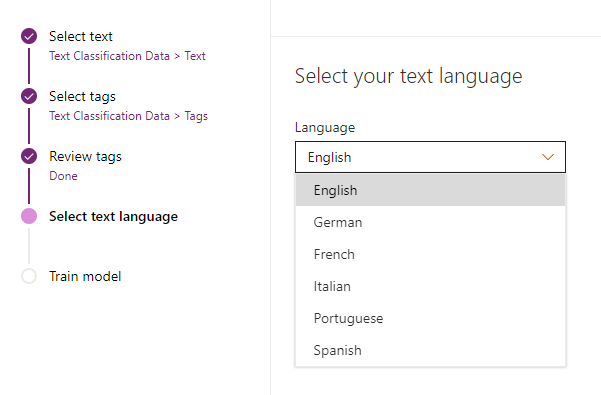
- The Train model screen shows the summary of model i.e. selected entity, fields and tags separator. Confirm these details and click on ‘Train’ button to train the model.
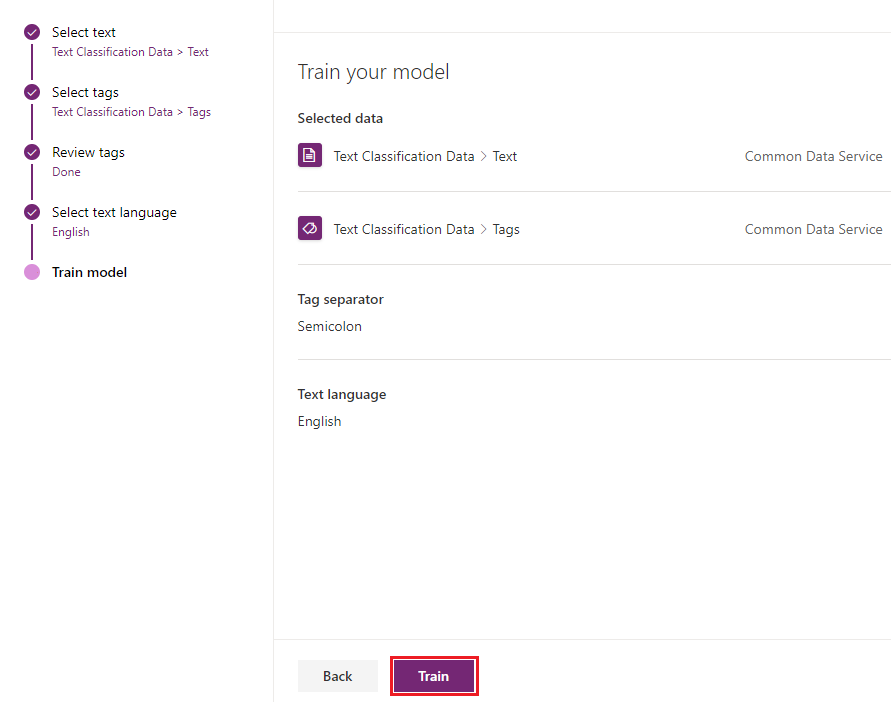
- Next navigate to newly created Text classification model. In model details screen we can see performance of the model. In our case it is showing 85%. It means model will give 85 times correct answers out of 100. If you are satisfied with the performance click on Publish button.
Before publishing the model you can do the quick test.
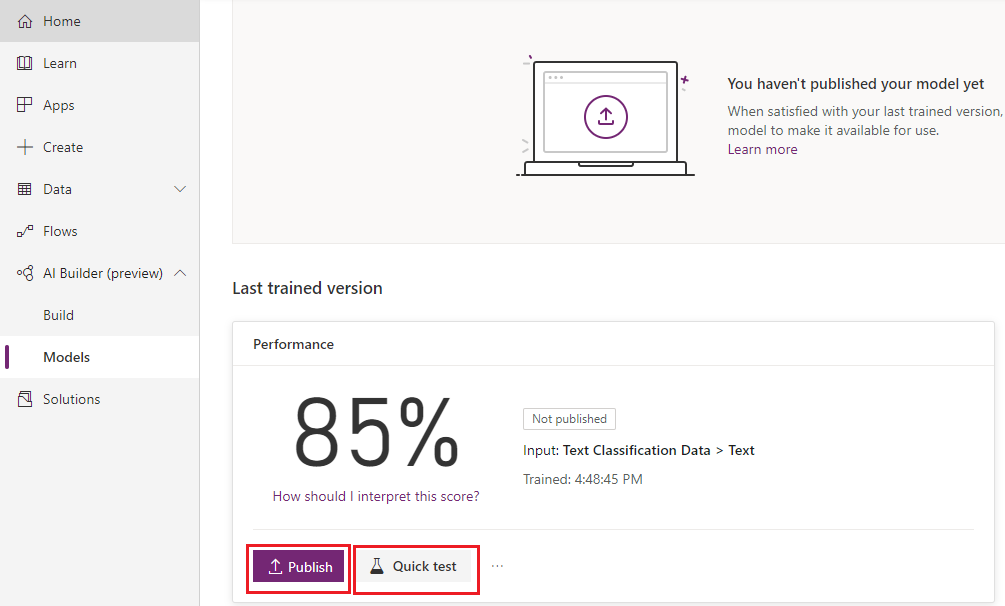
- After publishing we need to run it. Click on ‘Run’ The model goes into running stage. We can now use this model in Microsoft Flow or Power Apps. If you want to stop using this model then click on ‘Stop running’.
- When we publish the model, in the background a new entity gets created with N:1 relationship with the Entity that we created to store Text and Tags. The new entity is created with name in TC_<model name> format. In our case it got created as ‘TC_CustomersResponseClassification’. This is the entity where tags and their confidence level are stored.
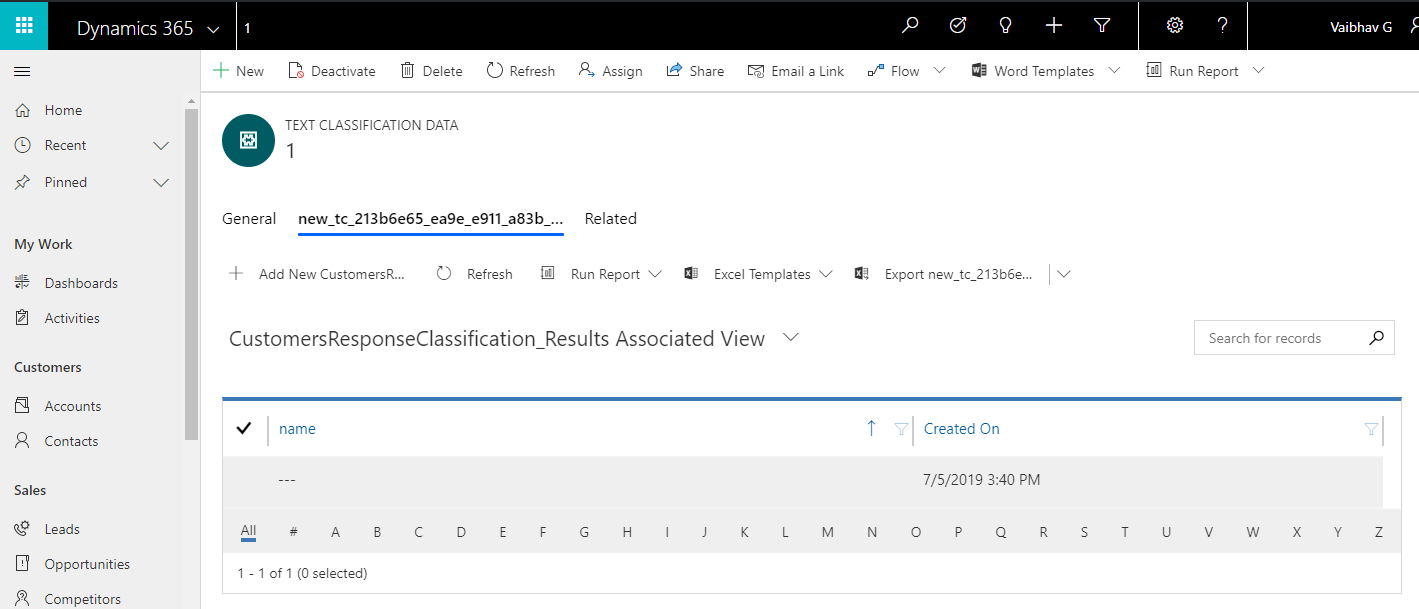
We have imported 122 records through CSV file in a new entity called ‘Text Classification Data’ entity and when we publish the model a new entity named as ‘CustomerResponseClassification_Results’ gets created. So, for each Text classification data record, a corresponding CustomerResponseClassification_Results entity record is created with Confidence level as shown in the below screen shot:
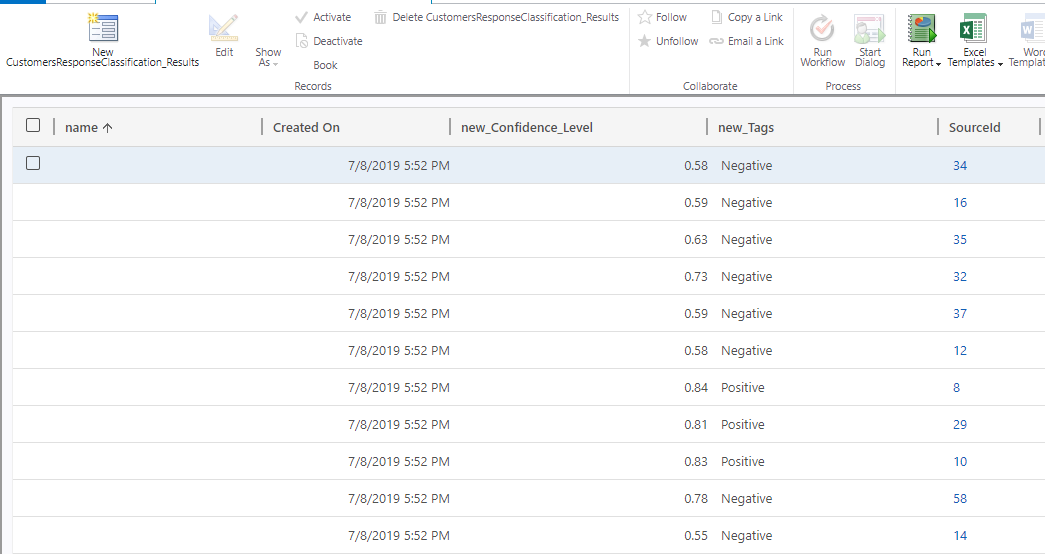
Use Microsoft Flow to categorise the email content using Text classification model: Now we can use the running text classification model in Microsoft Flow where we can pass the text coming from email or any other channel through it and can read the response.
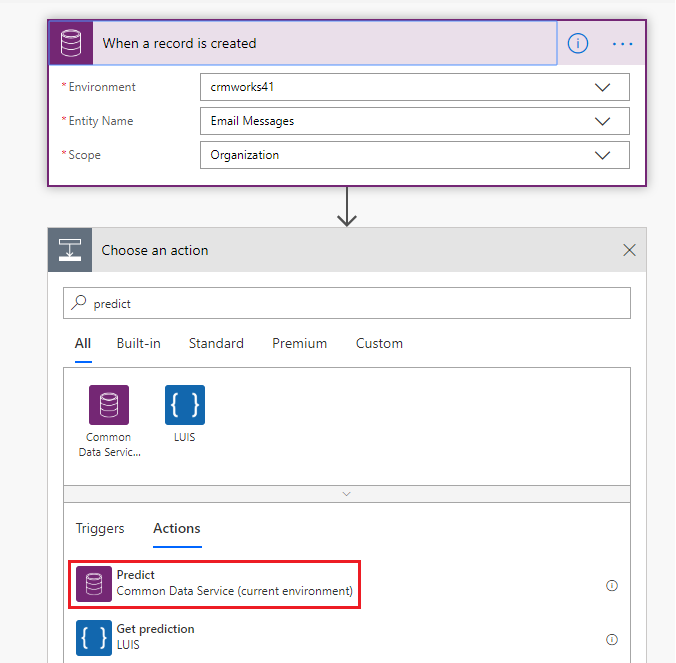
In Model, we have selected the model that we created for Text classification and added Request payload as shown in the below format;
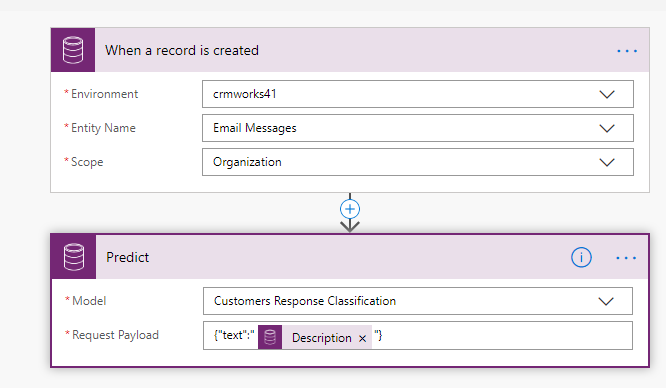
{“text”: “<text>”}
That’s it, this flow will trigger on creation of email and then Predict action will run Text classification model on the email content and return the response in JSON format as shown in the below screen shot.
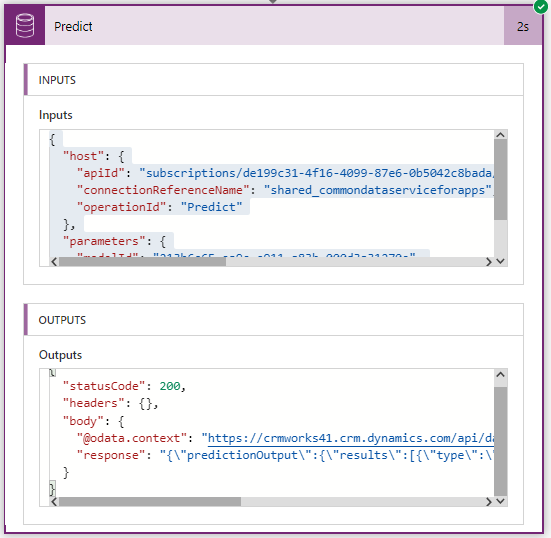
Input Text:
Good morning. We presented this product to our customer and they liked it. Good job.
Output:
Type: Positive
Score: 0.789058149
Input Text:
We really need some urgent help. Please can someone look into this issue as early as possible? Users are getting lot of errors.
Output:
Type: Negative
Score: 0.6402719
Now we can pass this JSON and read the suggested tags and its score. Read this blog to know how to read the response from Predict (Common Data Service) action.
Conclusion
AI Builder allows us to automate business process by adding artificial intelligence to it without having skills in Artificial intelligence or in data science.